DocRouter Architecture
DocRouter Architecture
Scalable document processing with AI-powered extraction
System Overview
DocRouter is built on a modern, cloud-native architecture designed for scalability, reliability, and ease of integration. The system processes documents through a multi-stage pipeline that combines OCR, AI analysis, and structured data extraction.
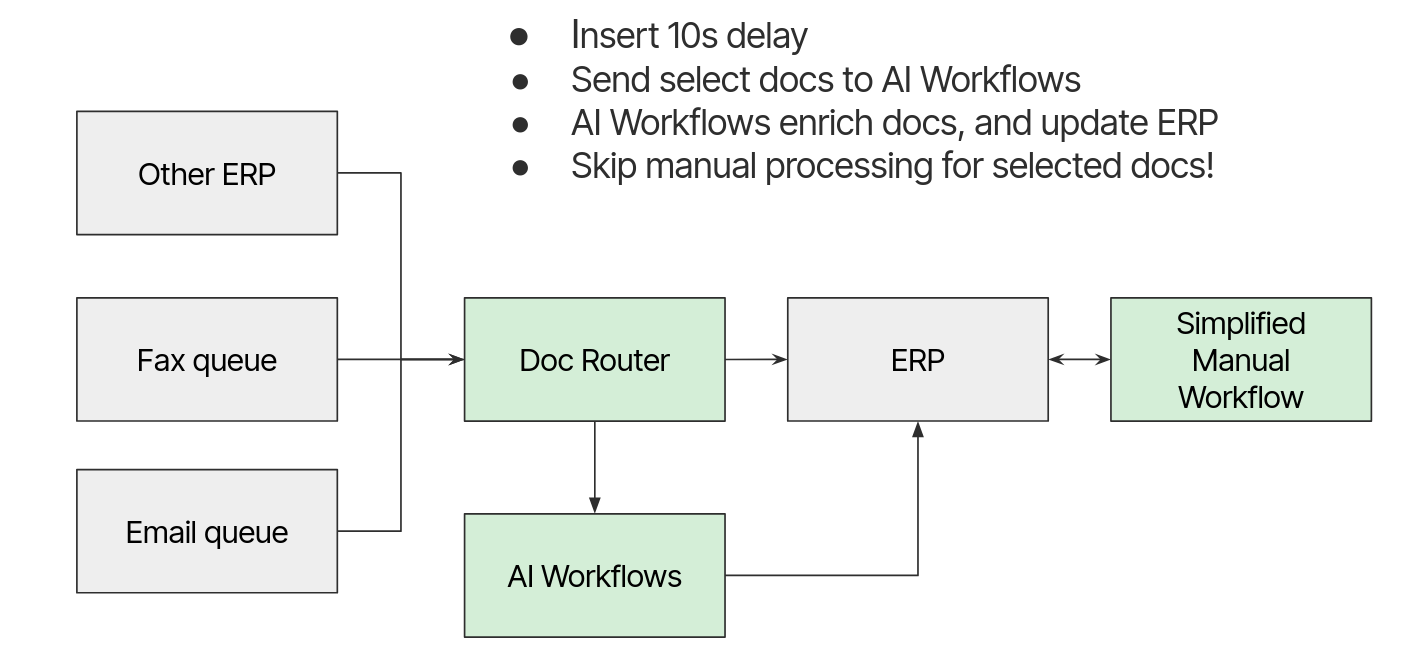
Core Components
Document Ingestion
- • Multi-format document support (PDF, images, Office docs)
- • Secure file upload with encryption
- • Automatic format detection and conversion
- • Batch processing capabilities
OCR Processing
- • Advanced optical character recognition
- • Handwriting recognition support
- • Multi-language text extraction
- • Table and form structure detection
AI Analysis Engine
- • Large language model integration
- • Custom prompt engineering
- • Schema-based data extraction
- • Confidence scoring and validation
Integration Layer
- • REST API for programmatic access
- • Webhook notifications
- • Third-party system integrations
- • Real-time status updates
Deployment Options
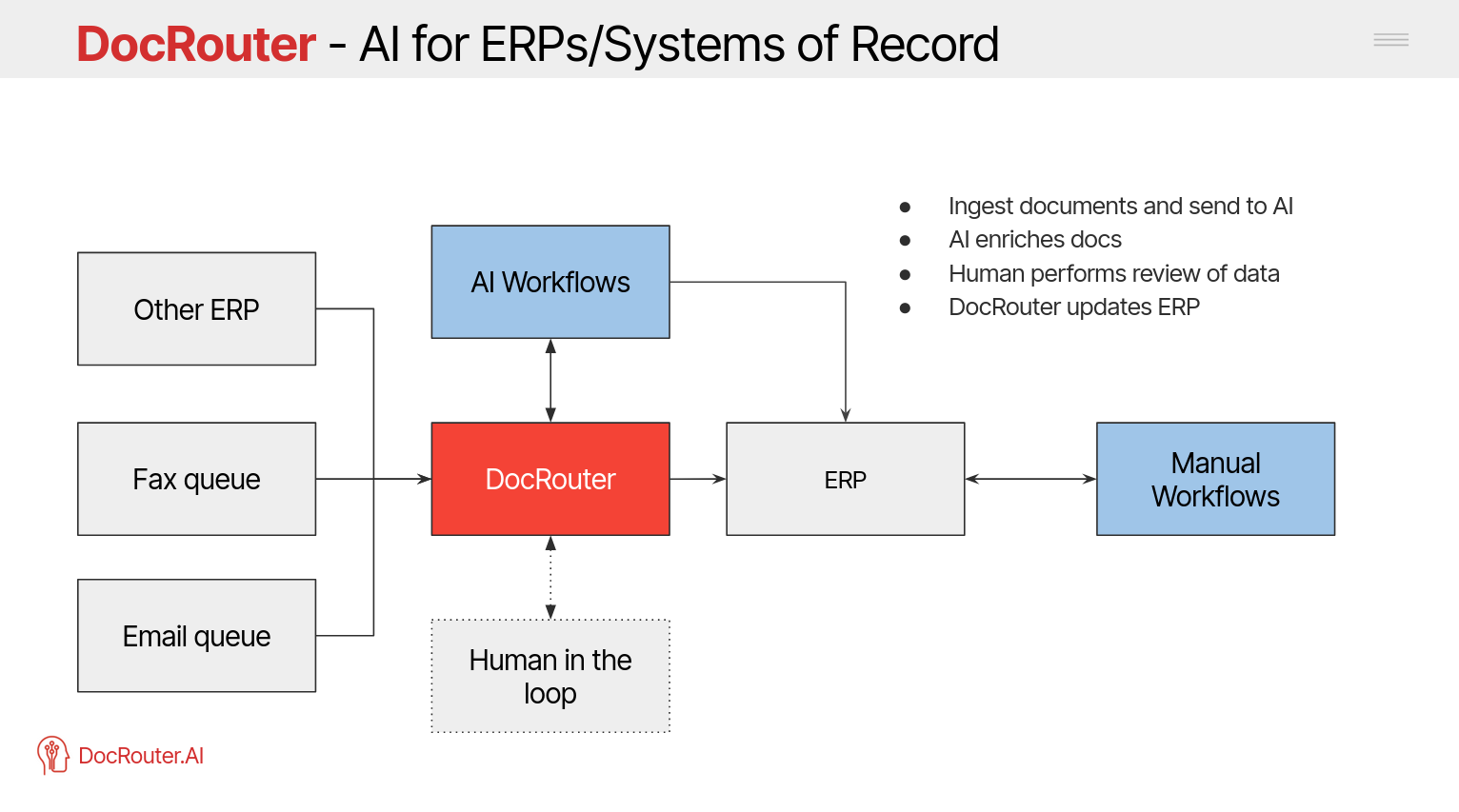
ERP Integration
Direct integration with existing ERP and business systems
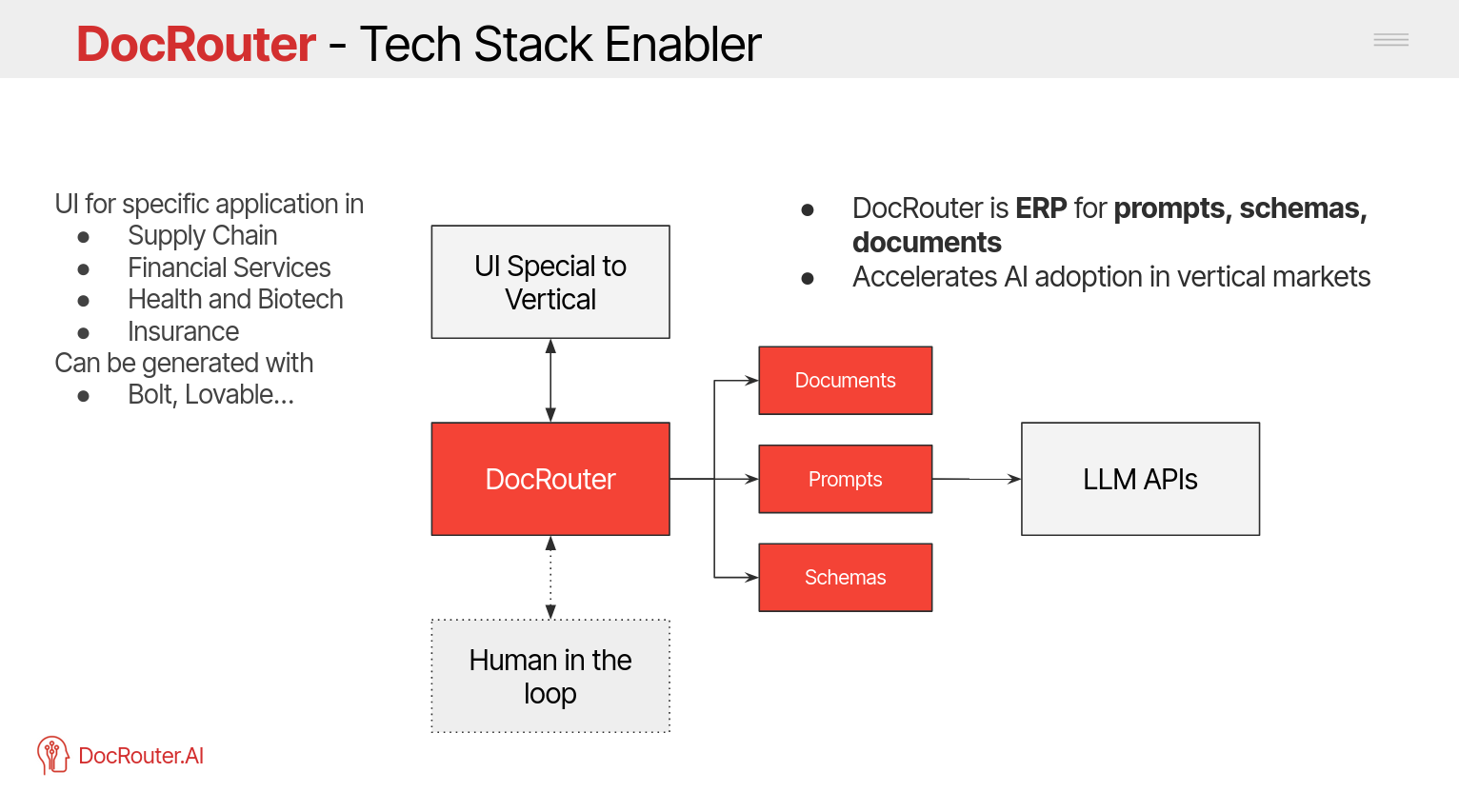
AI Tech Stack
Enabling component for AI-powered applications
Security & Compliance
🔒
Data Encryption
End-to-end encryption for documents in transit and at rest
📄
Audit Trails
Comprehensive logging and audit trails for compliance
🏢
On-Premise Options
Self-hosted deployment for maximum data control
Ready to Learn More?
Contact us to discuss architecture options and deployment strategies for your organization.