We recently shipped outbound webhook support in DocRouter. This post is a practical look at how we implemented it—both technically and with the AI tooling workflow that got it across the finish line.
If you just want to use webhooks (not implement them), see the docs: /docs/webhooks/.
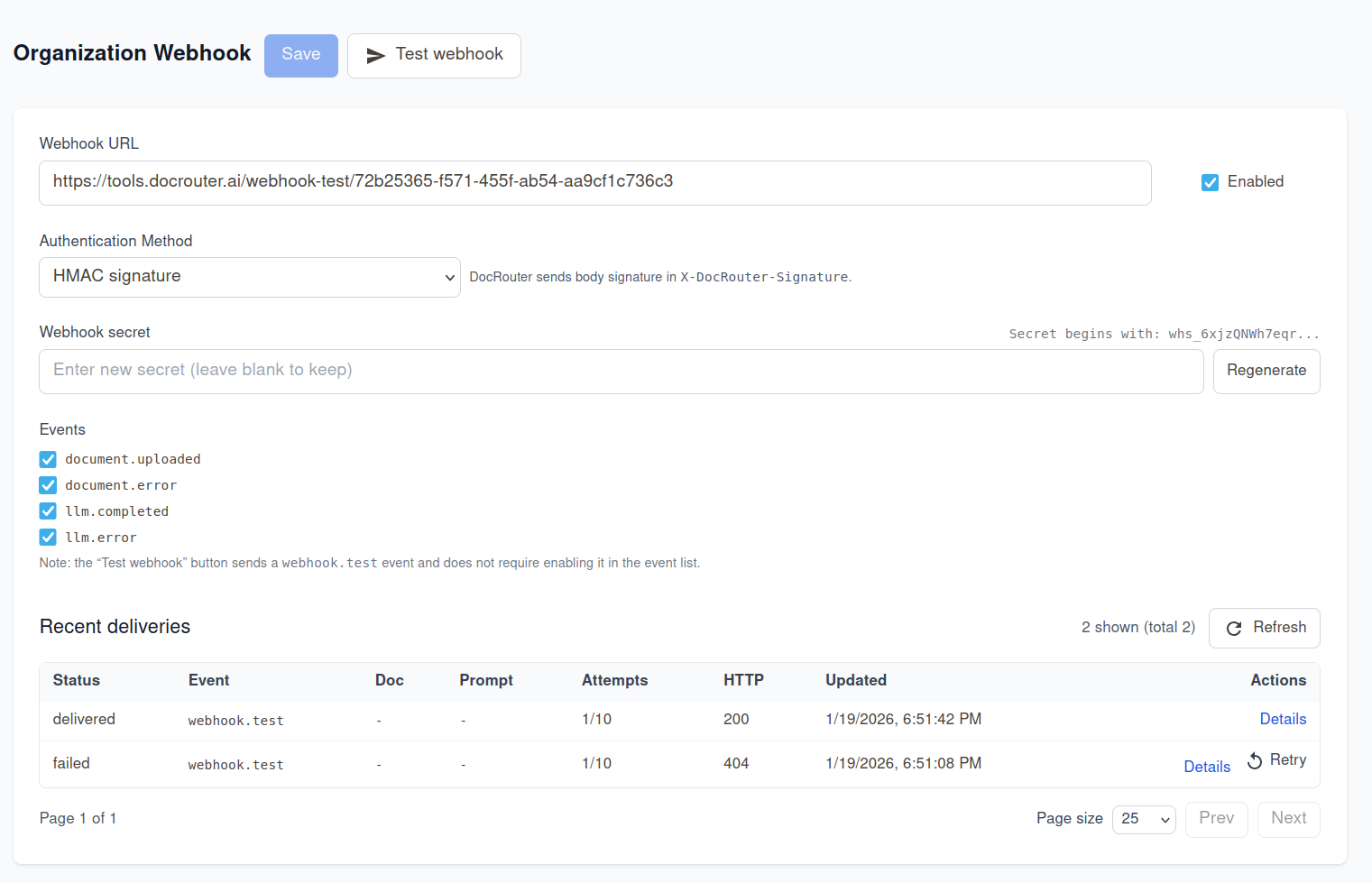
The AI workflow (what actually happened)
Here are the salient facts, in order:
- Cursor implemented the backend + worker + most frontend code in one shot.
- The webhook settings page was the exception: it required iteration and redesign (it was vibe-coded, but it took a few passes).
- Claude Code reviewed the one-shotted code and:
- Found one real bug.
- Flagged that the initial webhook pytest suite only had ~13% coverage.
- Then extended the tests to 100% coverage for the webhook module.
- Cursor generated the webhook documentation using Grok, which we then simplified into a short, “just the facts” doc page.
The big takeaway for me: one-shotting works best when the problem has a crisp “shape” (queue → worker → HTTP delivery). UI still wants iteration, even with strong models.
What we built (the product view)
At a high level:
- Organizations can configure a Webhook URL and an event allowlist.
- Deliveries are durable and retry automatically with exponential backoff.
- Auth supports:
- HMAC signatures (recommended)
- Static header auth (useful for tools like n8n)
- The UI shows recent deliveries and lets admins retry failed deliveries.
The core architecture (the engineering view)
We implemented webhooks as a small outbound delivery subsystem with three moving parts:
1) Persisted delivery records
Each event becomes a delivery record stored in MongoDB (collection: webhook_deliveries). This gives us:
- auditability (what was sent, when)
- retries without losing state
- a UI surface for “recent deliveries”
Each record tracks status (pending, processing, delivered, failed), attempt count, next-at timestamp, and last HTTP result.
2) A queue trigger + a retry scanner
New deliveries enqueue a message onto a webhook queue for immediate processing.
But queues aren’t enough by themselves for reliable retries (messages can be dropped, workers can crash). So the webhook worker also scans for due deliveries in the database and processes them even if no queue message exists.
This hybrid model—queue for fast path + DB scan for retries—keeps the system resilient without over-complicating it.
3) A sender with backoff + idempotency guidance
The sender:
- serializes a compact JSON body
- sends HTTP POST with timeouts
- classifies retryable errors (timeouts, 429s, 5xx)
- schedules retries with exponential backoff (bounded)
We also include an event_id in every payload and recommend consumers use it for idempotency/deduplication (webhooks are fundamentally at-least-once).
Headers and signing (what hits your endpoint)
When using HMAC auth, we sign:
- message:
"{timestamp}.{body}" - algorithm: HMAC-SHA256
- header:
X-DocRouter-Signature: sha256=<hex>
We also include:
X-DocRouter-EventX-DocRouter-Event-IdX-DocRouter-Timestamp
If you choose header auth instead, DocRouter sends your configured header name/value (encrypted at rest).
The settings UI (where iteration was unavoidable)
Everything “server shaped” was a clean one-shot: enqueue, store, claim, send, mark delivered/failed, retry with backoff.
The webhook settings page was different:
- it had more state, more edge cases (changing auth method, previews, regenerate secret)
- it needed a deliveries table, details drawer, retry action
- it had to fit into existing settings flows and permissions (org admin vs org user)
Cursor got us to a working UI quickly, but the “last mile” required the usual: restructure, redesign, rename, repeat.
Tests: from 13% to 100% (Claude Code’s biggest contribution)
Claude Code’s review did two things I really value:
1) it found a bug in the one-shotted implementation (fast feedback) 2) it forced the discipline of full behavioral coverage for the webhook module
We ended up with a webhook test suite that exercises:
- auth modes
- signature generation
- retryable vs non-retryable responses
- backoff scheduling
- delivery state transitions
- error handling paths
Documentation (generated with Grok, then edited down)
We also generated the initial docs in Cursor using Grok, then aggressively simplified them into a short “how to use it” page. The result is the doc you’ll actually want when wiring this into your system:
- events
- setup steps
- payload shape
- how to verify signatures
- how retries work
See: /docs/webhooks/
Closing thoughts
This was a good example of how I like to combine tools:
- Cursor for building quickly (especially when the architecture is clear)
- Claude Code for reviewing and “weaponizing” the tests
- a strong LLM (here: Grok) for first-pass docs, followed by human editing to keep them short
If you’re implementing webhooks in your own system, the pattern that worked best for us was: durable delivery records + queue trigger + DB-driven retries. It stays simple, it’s observable, and it degrades gracefully.